---
title: "Machine Learning"
...
\newpage{}
# Introduction
## Définitions
**Datascience**
- Mathématiques
- Programmation
- Connaissance métier
→ Résoudre des problèmes analytiques complexes de nature métier
**Intelligence artificielle** : Ensemble de techniques permettant aux machines d'imiter l'intelligence réelle.
**Machine Learning** : technologie d'IA permettant aux machines d'apprendre sans avoir été programmées explicitement à cette effet. Nécessite des données à analyser pour entrainer la machine, la faire apprendre et se développer.
## Croissance du ML : pourquoi maintenant ?
- Algorithme ancien mais technologie du big data récente permettant de calculer de plus en plus vite
- Données abondantes et diversifiées
- Puissance informatique et stockage de données de moins en moins chère
- Passage à l'échelle simple et peu couteux
## Méthodologie CRISP
CRoss-Industry Standard Process
1. Compréhension du métier
- Détermination des objectifs métier
- Détermination des objectifs data science
2. Compréhension des données
- Collecte des données
- Description des données
- Exploration des données
- Vérification de la qualité des données
3. Préparation des données
- Sélection de données
- Nettoyage de données
- Construction de nouvelles données
- Intégration de données
4. Modélisation
- Sélection de techniques de modélisation
- Construction des modèles
- Evaluation des modèles
5. Evaluation
- Evaluation des résultats
- Processus de révisions
- Détermination des étapes suivantes
6. Déploiement
- Planification du déploiement
- Planification de surveillance/maintenance
- Production du rapport final
\newpage{}
# Préparation de données (Features Engineering)
La phase de préparation de donnée est très importantes et prend même plus de temps que l'application des modèles. Cela consiste à préparer les datasets pour l'apprentissage notamment grâce au **Feature Engineering**.
Il s'agit d'un processus de tranformation des données dans un format facile à interpréter. Il faut présenter les données de façon à ce que les algorithmes de machines learning puissent plus facilement atteindre leurs objectifs d'apprentissage.
Le Feature Engineering comprend les tâches suivantes :
- Transformation des attributs : mise à l'échelle (scaling)
- Génération des attributs : calculer le ratio de deux attributs existants
- Extractions des attributs : ACP pour réduire la dimension
- Séléction des attributs : supprimer les colonnes inutiles ou redondantes
## Transformations importantes
- Scaling (mise à l'échelle)
- Standardisation
- Normalisation
- Encodage
- Par catégorie
- Encodage 1 parmis n
- Valeurs manquantes
- Remplacer par une constante
- Remplacer par la prédiction d'un modèle entrainé
- Séparation train-Test
- Séparation du jeu de données en une partie pour l'entrainement et une autre partie pour le test
- But : obtenir un estimateur non biaisé de la performance du modèle sur de nouvelles données
## Feature scaling
**Définition** : transformation qui consiste à adapter le domaine de variation des attributs de manière à ce que toutes les variables puissent être comparable selon la même échelle.
Cette étape peut améliorer les performance de certains algorithme (qui sont sensible à l'échelle) de façon significative.
- **Normalisation** (Min-Max Scaling) :
- Redimensionner l'attribut pour avoir que des valeurs qui varient entre 0 et 1
- ${ x_{norm} = \frac{x - x_{min}}{x_{max} - x_{min}} }$
- **Standardisation** (Z-score Normalization) :
- Redimensionner l'attribue de façon à obtenir des données dites centrées-réduite : moyenne nulle et écart type unitaire (1)
- ${x_{standard} = \frac{x - \mu}{\sigma}}$ avec $\mu$ la moyenne et $\sigma$ l'écart type
## Feature Encoding
**Définition** : opération qui mappe les valeurs d'une variable en un format numérique qui peut être interprété par un algorithme de machine learning.
S'applique surtout sur les variables catégorielles (modalités, classes) pour les encoder en nombres.
- **Encodage Catégorique**
- Chaque catégorie est associée à un nombre. Ex : "high" → 2, "medium" → 1, "low" → 0
- /!\ Limitation : Introduit un ordre dans les catégories qui n'est pas forcément appropriété
- **Encodage 1 parmis n** (one hot encoding)
- Chaque catégorie est associée à une nouvelle colonne binaire
- /!\ Limitation : Génère une collone par catégorie, peut être problématique si beaucoup de modalités
## Valeurs manquantes
Les données réelles ont souvent des valeurs manquantes.
Raisons possibles :
- Valeur indisponible / non enregistrée
- Observation corrompue
- Manque systématique du à un phénomène non aléatoire
Le traitement des données manquantes est une étape cruciale de la préparation de donnée car de nombreux algorithme de machine learning ne fonctionnent pas sur des données avec valeurs manquantes.
Il faut définir des règles de traitement de ces valeur qui dépend fortement de la nature des données.
Exemple :
- Supprimer les lignes avec valeur manquante
- Affecter la moyenne de la colonne aux valeurs manquantes
\newpage{}
# Machine Learning
## Types de données
### Qualification
La données peut être :
- Quantitative
- Discrète (ex : nb de place de parking)
- Continue (ex : salaire)
- Qualitative
- Nominale (ex : profession)
- Ordinale (ex : taille vestimentaire)
### Origine
- Données internes de l'entreprise
- SI
- CRM
- Datawarehouse
- Site web
- Logs
- Données des réseaux sociaux
- Données OpenData
### Données structurées
- Organisation logique
- Format identique
- Facilité de recherche
- Facile à stocker
Exemple :
- Données CSV
- SGBDR
### Données non structurées
- Organisation complexe
- Données hétérogènes
- Recherche complexe
- Difficile à stocker en l'état
Exemple :
- Email
- Donnée multimédia
## Cas d'usage
- La solution nécessite beaucoup de réglages
- La complexité du problème empêche toute solution classique
- Quand le problème ou son environnement est fluctuant → nécessité de de s'adapter automatiquement
- Problème complexe et grande masse de donnée
- Peut d'infos sur le problème sont disponibles
## Principe
On a des données historiques sur un phénomène donné. On cherche à prédire ce phénomène (variable cible) sur les données futures.
Composants :
- Input : donnée à partir de laquelle on veut prédire le phénomène
- Output : variable cible
- Data : données historiques sur le phénomène (couples input/ouput)
- Fonction cible : fonction idéale liée à ce phénomène
L'objectif du machine learning est d'approximer le mieux possible la fonction cible.
On fourni les données historiques en tant que données d'entrainement à un algorithme, qui va utiliser un ensemble d'hypothèse pour tester si elle approxime bien la fonction cible et retourner la fonction qui est la plus proche.
## Types d'apprentissage
Trois types d'apprentissage :
- Supervisé : prédire un donnée
- Classification : assigner une classe
- Régression : prédire une valeur
- Non supervisé : découvrir des patterns
- Clustering : rassembler des données
- Réduction de la dimension
- Par renforcement : apprendre par rapport à des pénalité / récompenses
**Apprentissage Supervisé** : Type d'apprentissage automatique guidé par la tâche consistant à apprendre une fonction de prédiction à part d'exemples étiquetés. La cible est donnue dès le début.
**Apprentissage Non Supervisé** : Type d'apprentissage automatique guidé par la donnée, qui s'opère sur des données non étiquetées dont le but est de découvrir les structures sous jacentes à ces données, des patterns. La cible n'est pas spécifiée.
**Apprentissage semi-supervisé** : Type d'apprentissage automatique qui utilise un ensemble de données étiquetées et non étiquetées.
**Apprentissage par renforcement** : Agent autonome qui apprend à interagir avec un environnement à partir d'exépriences de façon à maximiser une récompense quantitative. L'apprentissage consiste à définir des stratégie ou politique basée sur l'expérience permettant dans chaque situation de maximiser la récompense.
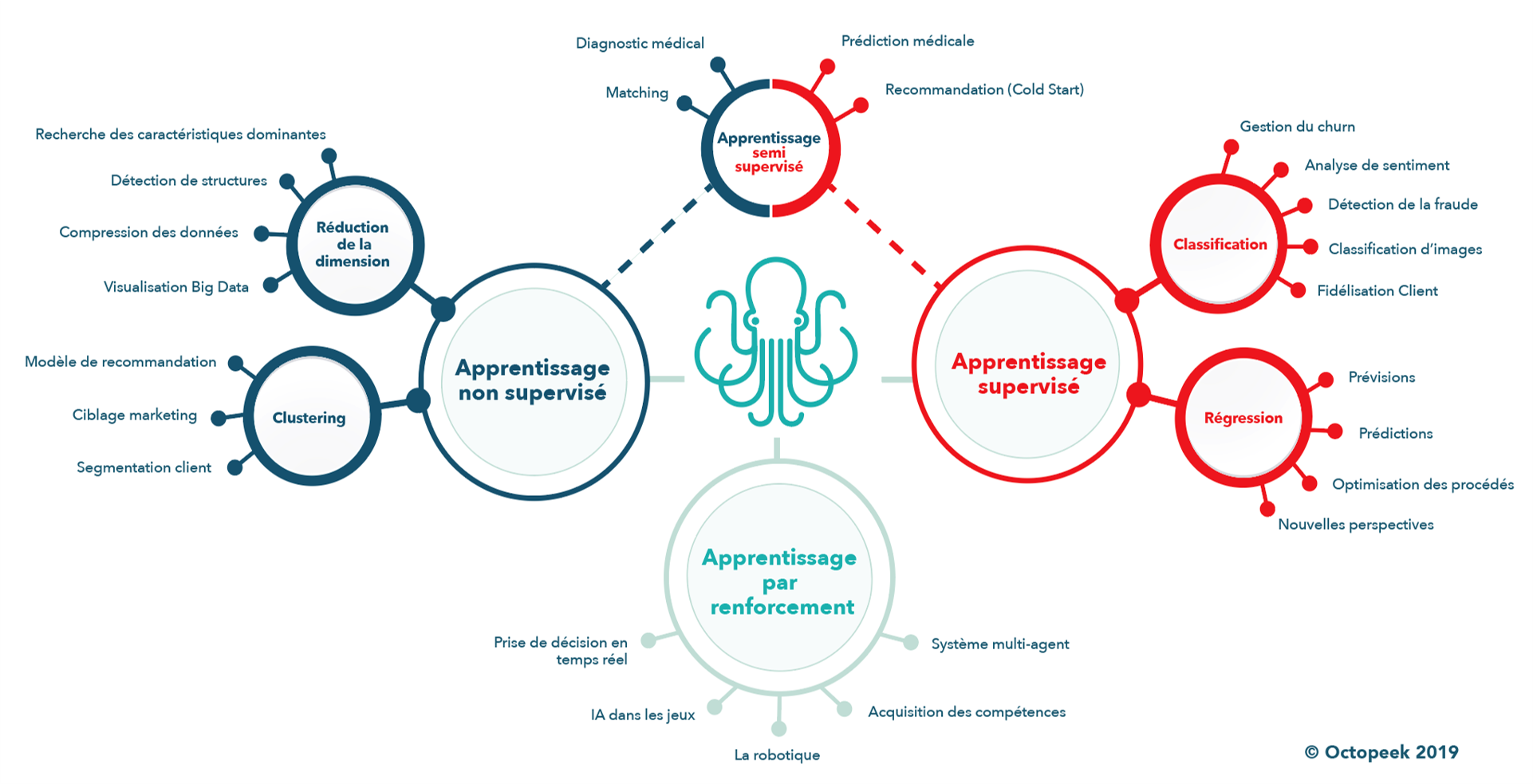
### Supervisé vs Non Supervisé
| | Non Supervisé | Supervisé |
| ------------- | ------------- | --------- |
| Type d'analyse| Descriptive | Prédictive|
| Résultat | Fourni directement | Fourni un modèle à appliquer sur des données|
| Objectifs | Mettre en évidence des faits présents mais chachés par le volume des données | Découvrir de nouvelles infos à partir des infos présentes |
| Procédé | Réduis, résume, synthétise les masses | Explique mieux les données
| Variable cible | Non | Oui |
\newpage{}
# Apprentissage Supervisé
## Principe
On a $n$ données (observations) étiquetées avec la valeur de la variable a prédire, couple :
- Ensemble de variables prédictives : variable dont on se sert pour prédire, ensemble $X$ vecteurs ${\overrightarrow{x_i} = (x_{i1},x_{i2}, ... ,x_{ip})}$ des $p$ variables prédictives
- Variable cible : variable à prédire ($y$)
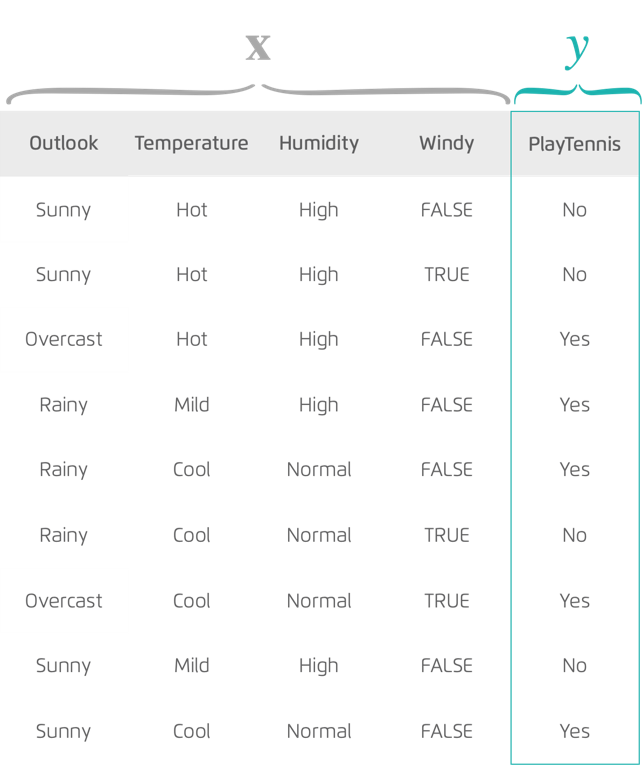
L'objectif est de prédire la sortie $y$ pour une nouvelle observation caractérisée par un veteur d'attributs ${\overrightarrow{x_i}}$.
On entraine l'algorithme sur ces données d'apprentissage étiquetées puis on l'exécute sur les données pour lesquels on a pas la réponse.
La variable cible peut être de nature quantitative ou qualitative, son type détermine la nature du problème (classification ou régression).
## Types d'Algorithmes
### Régression
La régression consiste à approcher une variable à partir d'autre qui lui sont correlées. Elle permet de prédire des variable quantitatives.
Algorithmes :
- Régression linéaire
- Régression logistique
### Classification
La classification permet de prédire des variables **qualitatives**, c'est à dire attribuer une classe (ou catégorie) à chaque nouvelle observation à prédire.
Algorithmes :
- KNN (K Nearest Neighbours)
- SVM (Support Vector Machine)
- Decision Trees & Random Forests
Le but du classifieur est de séparer des échantillons. Les échantillons séparés rassemble des observations aux propriétés similaires.
On parle de modalités de la variable cible pour désigner les valeurs uniques (connues et définies à l'avance) prises par la variable cible.
## Régression : Régression Linéaire
Avec un modèle de prédiction linéaire, on veut prédire la valeur d'une variable continue :
- Poids en fonction de la taille
- Prix d'appartement en fonction de la superficie, étage et quartier
- Consommation d'électricité en fonction de la température et de l'isolation
Le but de cet algorithme est de trouve la fonction linéaire qui modélise le mieux la relation en variables prédictive et variable cible :
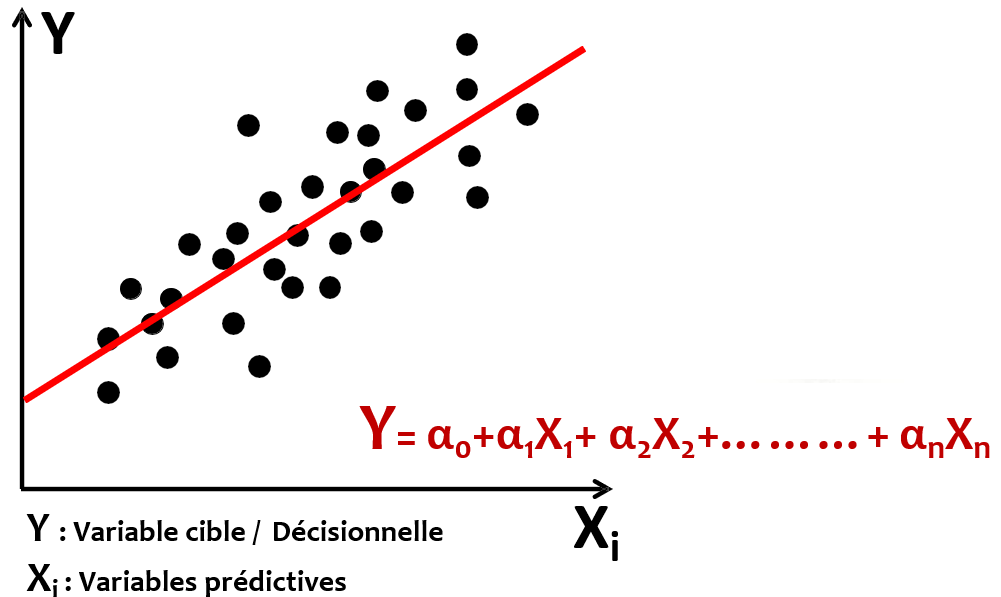
La droite est celle qui :
- Représente le mieux les données
- Résume le mieux le nuage de points
- La droite qui explique mieux les $Y$ en fonctions des $X_i$
La méthode des moindres carrés consiste à trouver les valeurs des coefficients *ai* qui minimisent la somme des carrés des écarts entre les valeurs réelles *Y* et les valeurs prédites avec le modèle.
La distance d'un point à la droite est la distance verticale entre l'ordonnée $y_i$ du point observé ${(x_i,y_i)}$ et l'ordonnée $y_i'$ du point correspondant sur la droite ${(x_i',y_i')}$. On note cet écart ${\epsilon_i = y_i - y_i'}$.
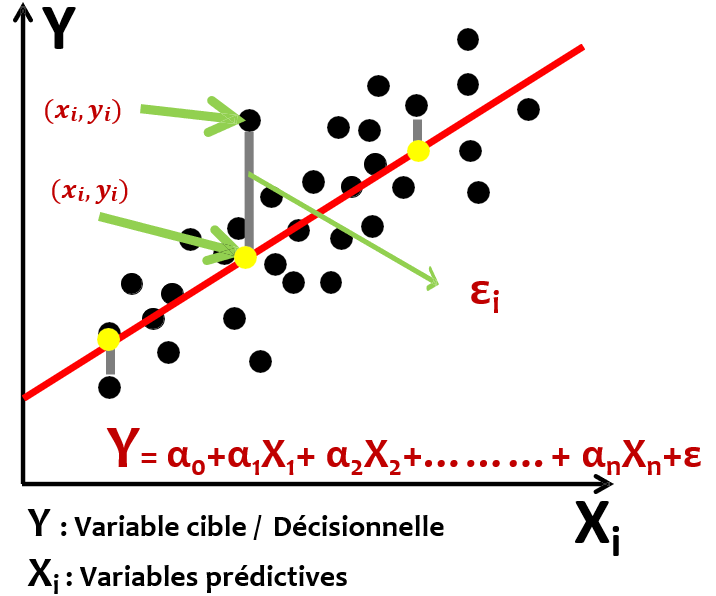
L'objectif est de minimise ${\epsilon_i^2 = (y_i - y_i')^2}$
La précision des coefficients est optimale si :
- La variance d'erreur est faible : la droite de régression passe bien au milieu des points
- La dispersion des *X* est forte : les X couvrent bien l'espace de représentation
## Classification : Support Vector Machine (SVM)
### Principe
Le but de SVM est de générer un Hyperplan (au sens : plan vectoriel) à partir des données d'entraînement qui va séparer les données. L'Hyperplan possède une marge, qui correspond à la distance entre ce dernier et les observations les plus proches.
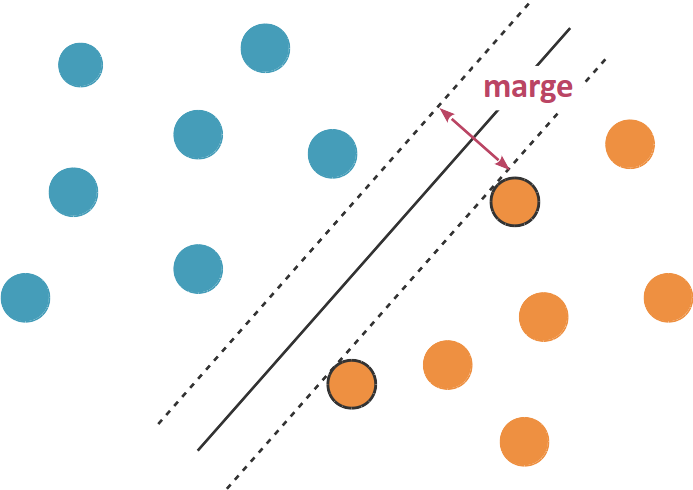
Pour avoir un classifieur efficace, la marge doit être maximale.
### Données linéairement séparables
SVM permet de traiter des données séparables linéairement ; séparables par une droites.
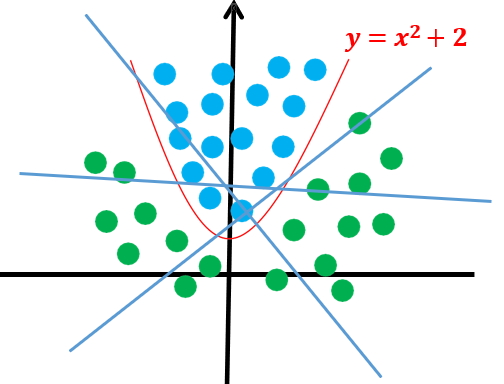
Pour des données non séparables linéairement, on peut procéder à une transformation sur les données pour les rendre linéairement séparables, ou alors utiliser d'autre technologies.
### Paramètres
#### Régularisation
Il faut bien choisir car si :
- Régularisation trop grand → sur apprentissage
- Régularisation trop grand → sous apprentissage
#### Gamma
Définit à quel point les valeurs extrêmes sont prises en compte :
- Gamma faible : les points les plus éloignés de la ligne plausibles sont pris en compte
- Gamma élevé : les points les plus proches de la lignes plausible sont pris en compte
#### Kernels
La fonction Noyau est la fonction mathématique utilisée pour transformer les données en utilisant l'algèbre linéaire.
Exemple de fonction Noyau :
- Linéaire
- Polynomiale
- Base radiale
- Sigmoïde
### Conclusion
- Marche très bien avec une marge de séparation claire
- Efficace dans les espaces de grande dimension
- Efficace quand plus de dimensions que d'observations
- Efficace en mémoire : utilise un sous ensemble des points d'apprentissage dans la fonction de décision (vecteur de support)
## Classification : K Nearest Neighboors (KNN)
### Principe
L'algorithme charge en mémoire tous les cas disponible et classe les nouveaux cas en fonction d'une mesure de similitude, en général une distance mathématique (ex : distance euclidienne).
Une nouvelle instance est classée par un vote majoritaire de ses voisins. L'objet est affecté à la classe la plus courante parmi ses K plus proches voisins.
Le nombre de voisins à considérer K est fourni par l'utilisateur.
En cas d'égalité, l'affectation se fera à la classe la plus proche en moyenne.
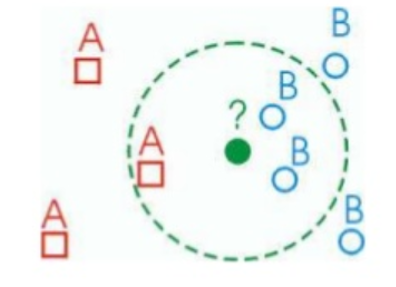
### Fonctions de distance
Soit $k$ le nombre de dimensions et
- Euclidienne : $\sqrt{ \sum_{i=1}^{k} (x_i - y_i)² }$
- Manhattan : $\sqrt{ \sum_{i=1}^{k} | x_i - y_i | }$
- Minkowski : $\sqrt[q]{\sum_{i=1}^{k} (| x_i - y_i |)^q)}$ avec $q$ ordre de la distance de Mikowski.
On utilise une distance d'ordre supérieur comme la distance de Minkowski si on veut donner plus d'importance aux valeurs elevées par rapport aux autres valeurs.
### Choix de K
Si K est trop petit, il est sensible aux points de bruits. Un K plus grand fonctionne bien mais un K trop grand peut inclure des points majoritaires d'une autre classe et augmente également le temps de calcul.
En général : $K < \sqrt{n}$ avec $n$ le nombre d'exemples.
Technique d'optimisation pour trouver la valeur de K optimale :
- Entrainer différents modèles avec des valeurs de K différentes
- Les évaluer avec des données de tests
- Séléctionner la valeur de K dont le modèle qui maximise le taux de réussite
### Normalisation des features
La distance entre voisins peut être dominé par des attributs à des échelles différentes. Il convient donc de normaliser, standariser ces features en les centrant et en les réduisant :
- Retrancher la moyenne
- Diviser par l'écart-type
On obtient alors des données dites centrées réduites, indépendante de l'unité ou de l'échelle, possédant la même moyenne et la même dispersion.
### Conclusion
Apprentissage paresseux :
- Pas d'apprentissage avant le classement, tous les calculs sont faits pendant
- Technique d'indexation recquise pour les grands datasets
- Fort coût en mémoire
## Arbres de décision : Algorithme de CART et indice de GINI
### Principe
Arbres utilisés dans l'informatique décisionnelle. Composé de 3 types de noeuds :
- Noeud racine : point de départ, premier test qu'on fait (variable testée la plus discrimiante, la plus liée avec la variable à prédire)
- Noeuds non terminaux : test sur une variable
- Feuilles : résultat de décision
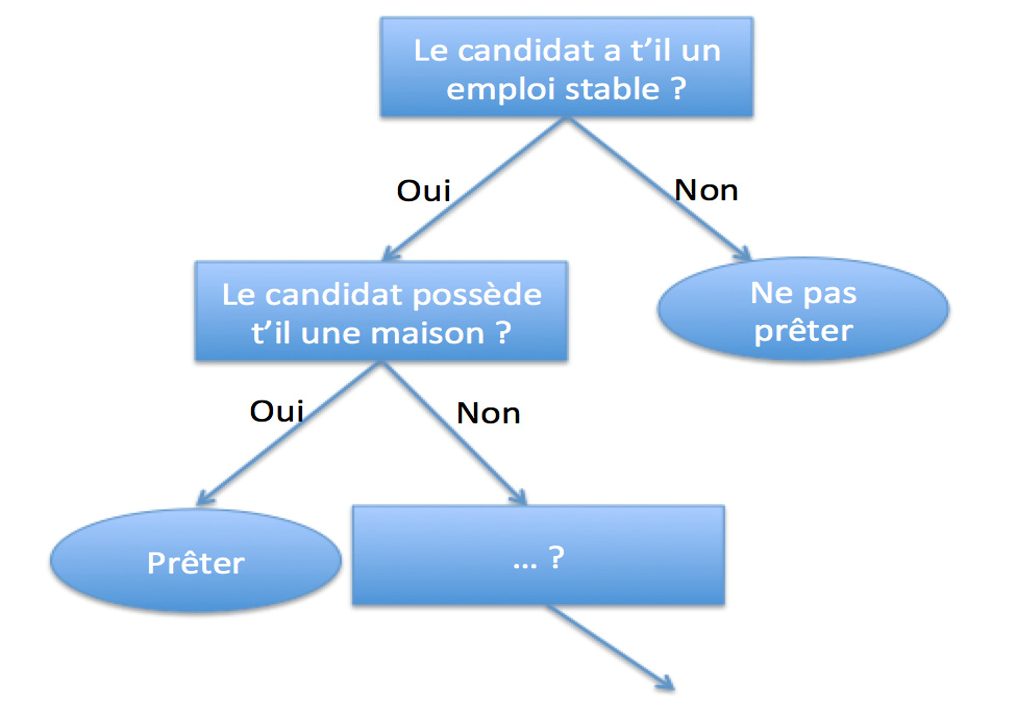
Les arbres de décision peuvent être utilisés aussi bien dans des problèmes de régression que dans des problèmes de classification.
La problématique est le choix des variable dans les noeuds. Si on a 10 variable prédictives, laquelle placer dans la racine ? Dans quel ordre les placer ensuite ?
Il existe plusieurs méthodes pour choisir le meilleur attribut à placer dans un noeuds, la meilleure est l'indice de GINI, car il est le seul à répondre au problèmes suivants :
- Comment choisir la variable à segmenter ?
- Comment déterminer le seuil de coupe en cas de variable continue
- Comment déterminer la bonne taille de l'arbre ?
L'algorithme de CART est un algorithme qui utilise l'indice de GINI pour construire un arbre de décision :
- Parmi les plus performant et répandu
- Accepte tout type de variable
- Utilise comme critère de séparation l'indice de GINI : ${GINI = 1 - \sum_{i=1}^{n} f_i^2}$
- $n$ : nombre de classes à prédire (nombre de feuilles différentes ; modalités de la variable cible)
- $f_i$ : fréquence de la classe dans le noeud
- La variable la plus discriminante (à la racine de l'arbre) doit maximiser : ${ GINI_{avant séparation} - \sum_{i=1}^n GINI(fils_n)}$
### Déroulement
On déroule l'algorithme de CART avec les variables prédictives :
- M : Moyenne des montant sur le compte du client
- A : Tranche d'âge du client
- R : Localité de résidence du client
- E : Le client a fait des études supérieures
Et la variable cible I : Le client consulte ses comptes en utilisant internet.
Les données d'entraînement sont les suivantes :
| Client | M | A | R | E | I |
|--------|--------|-------|---------|-----|-----|
| 1 | moyen | moyen | village | oui | oui |
| 2 | élevé | moyen | bourg | non | non |
| 3 | faible | agé | bourg | non | non |
| 4 | faible | moyen | bourg | oui | oui |
| 5 | moyen | jeune | ville | oui | oui |
| 6 | élevé | agé | ville | oui | non |
| 7 | moyen | agé | ville | oui | non |
| 8 | faible | moyen | village | non | non |
On commance par calculer l'indice de GINI avant séparation, en calculant l'indice de GINI se basant sur la variable cible :
${GINI_{avant séparation} = 1 - \sum_{i=1}^{n} f_i^2}$
${GINI_{avant séparation} = 1 - (( \frac{3}{8} )^2 + ( \frac{5}{8} )^2) }$
${GINI_{avant séparation} = 0.46875}$
- $\frac{3}{8}$ correspond à la fréquence des "oui" pour la variable cible
- $\frac{5}{8}$ correspond à la fréquence des "non" pour la variable cible
On calcule ensuite l'indice de GINI de chaque modalité de chaque variable pour trouver la plus discriminante.
Pour la variable M, modalité "faible" :
${ GINI_{Mfaible} = 1 - (\frac{1}{3}^2 + \frac{2}{3}^2) }$
${ GINI_{Mfaible} = 0.44444444 }$
- $\frac{1}{3}$ correspond à la fréquence des I = "oui" pour la variable cible pour les observation où M = "faible"
- $\frac{2}{3}$ correspond à la fréquence des I = "non" pour la variable cible pour les observation où M = "faible"
Pour la variable M, modalité "moyen" :
${ GINI_{Mmoyen} = 1 - (\frac{2}{3}^2 + \frac{1}{3}^2) }$
${ GINI_{Mmoyen} = 0.44444444 }$
- $\frac{2}{3}$ correspond à la fréquence des I = "oui" pour la variable cible pour les observation où M = "moyen"
- $\frac{1}{3}$ correspond à la fréquence des I = "non" pour la variable cible pour les observation où M = "moyen"
Pour la variable M, modalité "elevé" :
${ GINI_{Melevé} = 1 - (\frac{0}{2}^2 + \frac{2}{2}^2) }$
${ GINI_{Melevé} = 0 }$
- $\frac{0}{2}$ correspond à la fréquence des I = "oui" pour la variable cible pour les observation où M = "elevé"
- $\frac{2}{2}$ correspond à la fréquence des I = "non" pour la variable cible pour les observation où M = "elevé"
Une fois qu'on a calculé les indices de GINI de chaque modalité de la variable prédictive M, on peut calculer l'indice de GINI de la variable M elle même :
${GINI_{M} = GINI_{avant séparation} - ( GINI_{Mfaible} + GINI_{Mmoyen} + GINI_{Melevé} )}$
${GINI_{M} =0.46875 - ( 0.444444 + 0.444444 + 0 )}$
${GINI_{M} = -0.4201388}$
On répète ce processus pour chaque variable prédictive.
${GINI_{A} = -0.03125}$
${GINI_{R} = -0.9201388}$
${GINI_{E} = -0.01125388}$
Plus l'indice de GINI d'une variable est elevé, plus cette variable est discriminante, et plus le noeuds de l'arbre qui y correspond sera haut dans l'arbre.
La variable avec l'indice de GINI le plus élevé sera à la racine de l'arbre. Ici il s'agit de E. Ainsi on regarde les valeurs de I en fonction de celles de E :
- Pour les observations où E = "non", on a toujours I = "non"
- Pour les valeurs où E = "oui" on parfois I = "non" et parfois I = "oui"
On a donc :
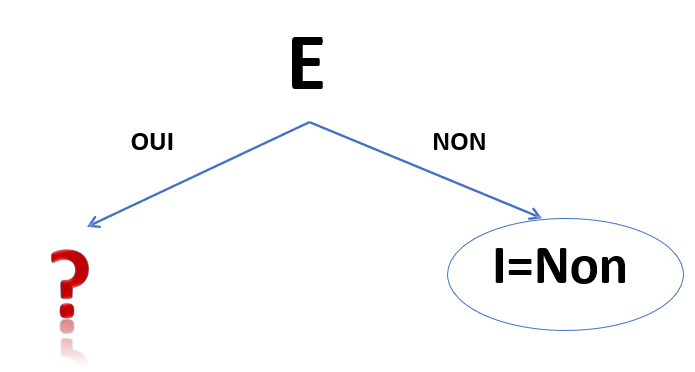
Pour constuire le noeud suivant de l'arbre, on va réitérer la même procédure pour les variable prédictives restantes en ne considérant plus que les cinq observations où E = "oui".
${GINI_{M_{E=oui}} = 0.0355556}$
${GINI_{A_{E=oui}} = 0.48}$
${GINI_{R_{E=oui}} = 0.0355556}$
La variable la plus discriminante est A. On regarde les valeurs de I en fonction de celles de A quand E = "oui" :
- Pour les observations où A = "jeune", I = "oui"
- Pour les observations où A = "moyen", I = "oui"
- Pour les observations où A = "âgé", I = "non"
On remarque qu'il n'existe aucune combinaison de valeur de E = "oui" et de A pour lesquels I peut prendre différentes valeurs. L'arbre est donc complet. On a :
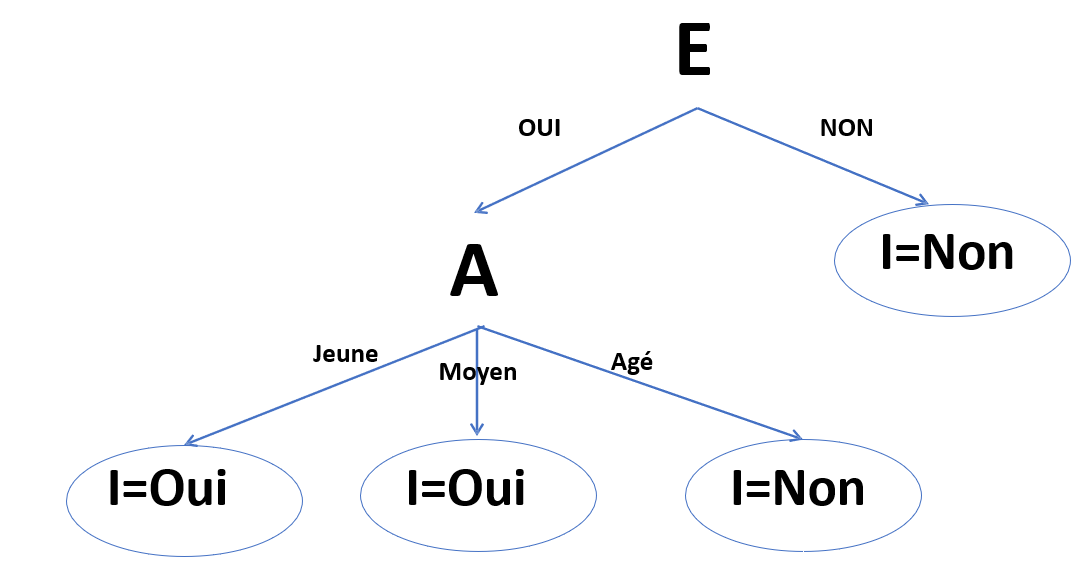
A partir de ces données, seul A et E suffisent à statuer sur I. On dispose désormais d'un arbre de décision pour faire des prédictions.
## Forêts aléatoires
### Principe
- L'union fait la force, au lieu d'utiliser un seul arbre, on utilise des dizaines/centaines d'arbres de décision différents.
- Forêt : ensemble d'arbre
- Aléatoire : chaque après utilise un sous ensemble aléatoire de l'ensemble des variables. La taille de cet ensemble est la racine carrée du nombre total de variables
Résultat de prédiction :
- Dans un cas de classification, la classe prédite par le modèle est pas classe majoritaire, prédite par le plus grand nombre d'arbre
- Dans un cas de régression la valeur prédite sera la moyenne de toutes les valeurs prédites par l'ensemble des arbre
### Avantages & Inconvénients
Avantages :
- Prédiction très rapide
- Efficace pour les valeurs extrêmes
- Efficace sur des observations de grande dimension
- Multi-classe par nature
Inconvénients :
- Apprentissage souvent long
- Valeurs extrêmes mal estimées dansles cas de régression
\newpage{}
# Apprentissage Non Supervisé
## Le clustering (segmentation)
Ensemble de méthodes d'apprentissage non supervisé qui visent à diviser un ensemble de données en différents sous ensemble homogènes de façon à ce que les données de chaque partition partageant des caractéristiques communes, qui correspondent le plus souvent à des critères de proximité que l'ont définit en introduisant des mesures de distances entre individus et / ou classes.
Exemples d'application :
- Banque / assurance :
- Catégoriser la clientèle : chercher un profil qui représente chaque classe
- Regrouper les clients selon des caractéristiques communes, pour cibler le marketing
- Médecine
- Déterminer des segments de patients pour établir des protocoles thérapeutiques
- Retrouver des comportements similaires
- Biologie / Zoologie / Ethnologie / Science humaines
- Expliquer les relations en espèces, races, genre, familles
- Retrouver de nouvelles répartitions
- Profiling
- Analyse sémantique, analyse de sentiments
- Analyse et mesure de tonalité d'un contenu textuel
- Catégoriser des concepts et des entitées nommées
- Construction d'aggrégateurs synthétiques à partir des flux d'actualité
Deux individus se ressemblent si les points dans le nuage sont proche → nécessité d'une mesure de distance mathématique :
- Euclidienne
- Mahalanobis
- Manhattan
- Ward
Familles de méthodes :
- Partionnement :
- K-Means
- PAM
- BFR
- CURE
- Hiérarchique :
- CAH
- Densité :
- db-scan
- OPTICS
## K-Means (Méthode de centres mobiles)
Algorithme de clustering le plus connu et le plus utilisé.
### Principe
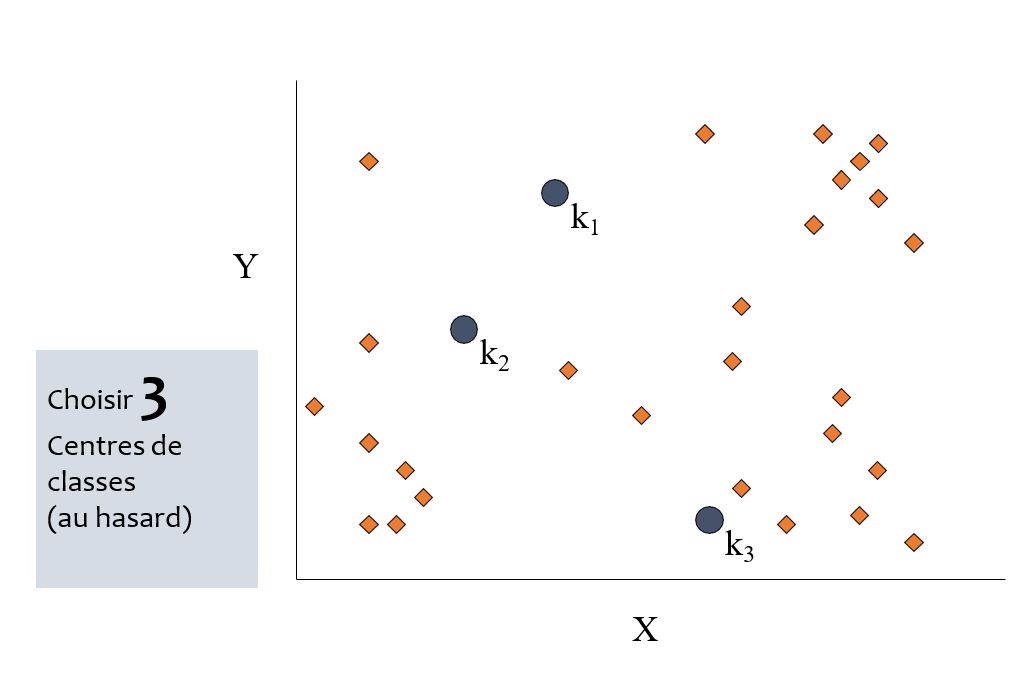
Déroulement :
1. Entrée : Soit k le nombre de groupes recherchés
2. Initialisation : Désigner aléatoirement le centre des groupes
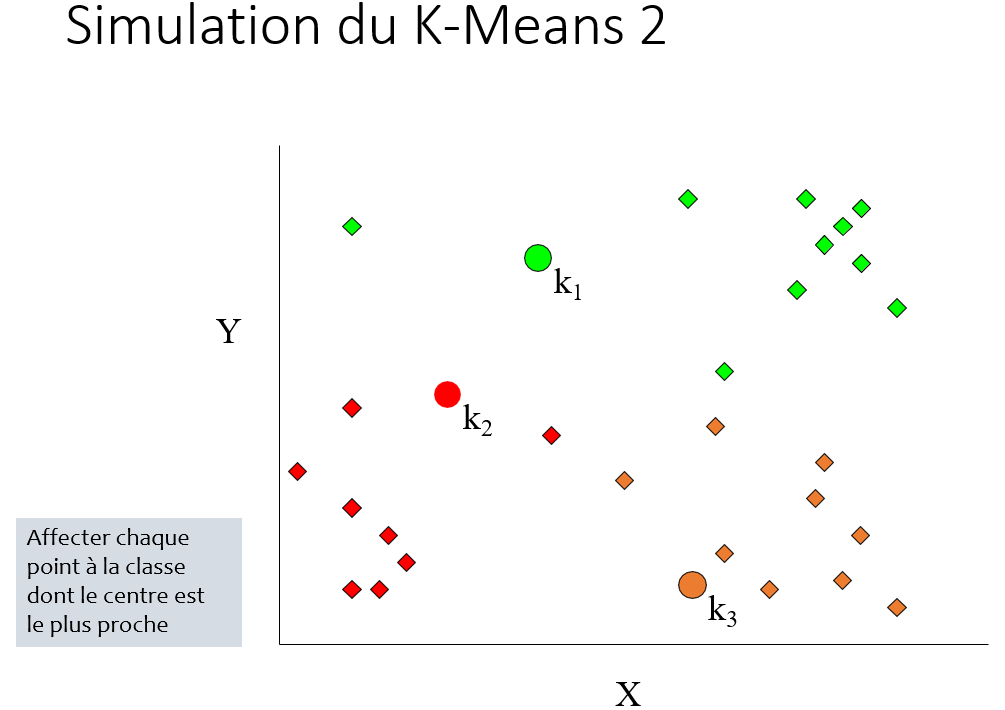
3. Répéter :
- Affecter chaque cas au groupe dont le centre est le plus proche
- Recalculer le centre de chaque groupe : déplacer le centre d'une classe vers la moyenne de cette classe
- Jusqu'à :
- Stabilisation des centres
- Nombre d'itérations maximales atteint
- Stabilisation de l'inertie totale de la population
Exemple :
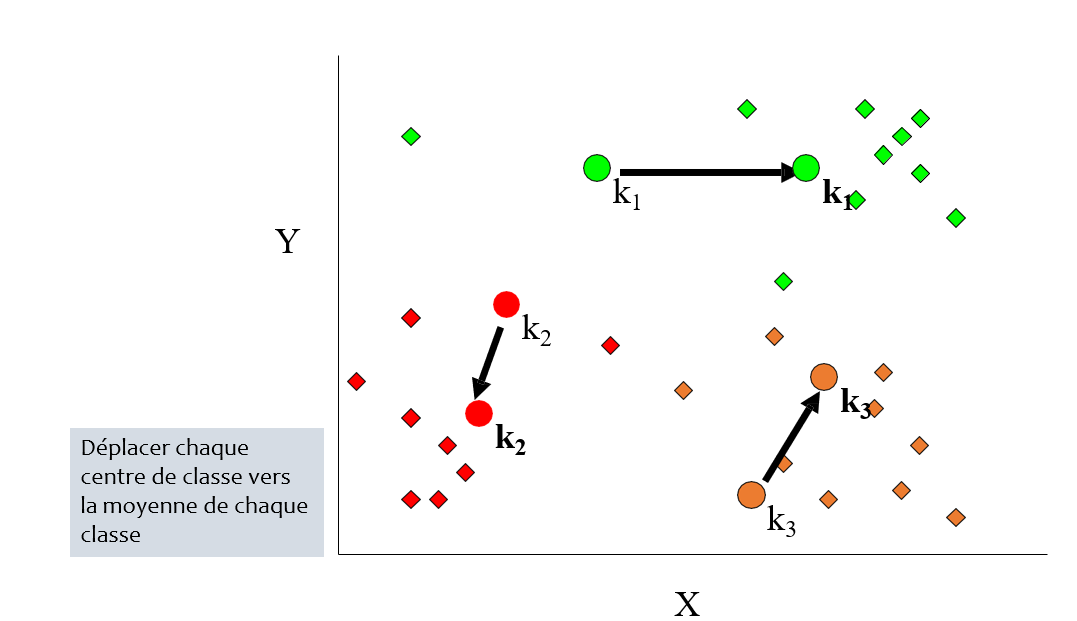
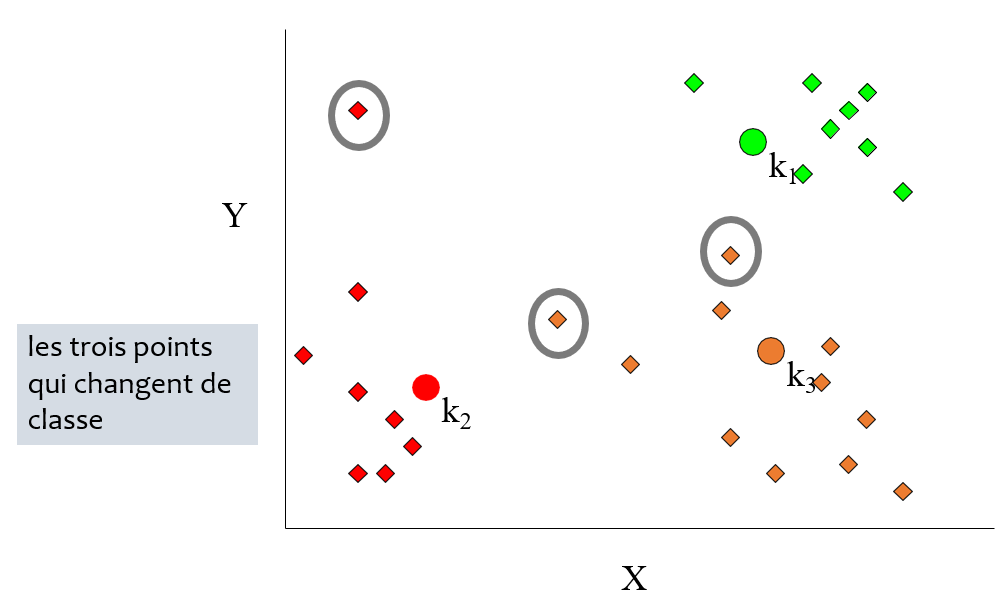
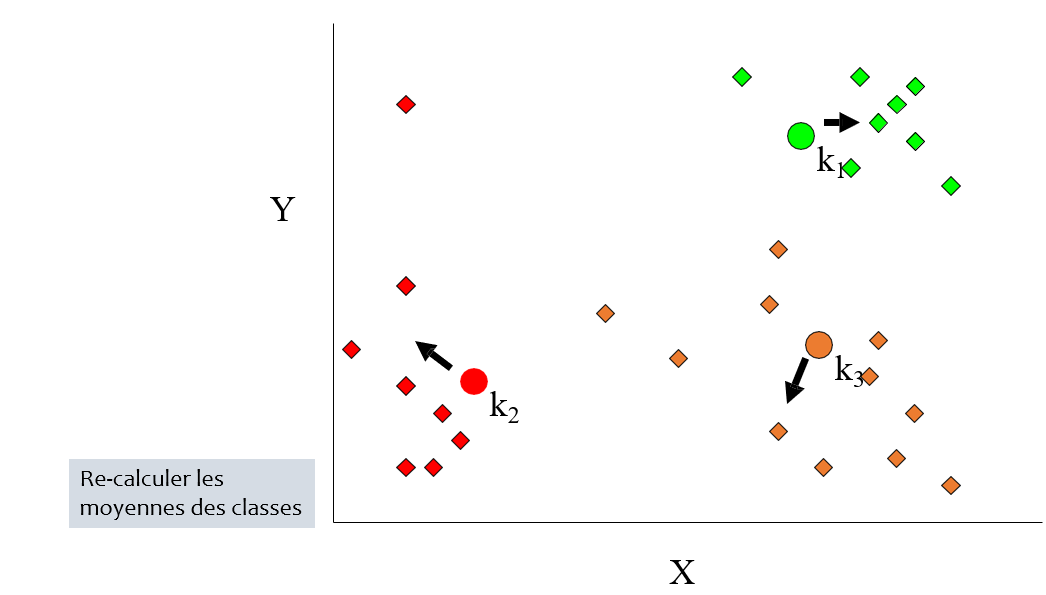
### Conclusions
Points faibles :
- Choix de nombre de groupes subjectifs : on ne sait pas toujours combien de classes doivent être présentes dans l'échantillon
- Ne trouve pas nécessairement la configuration la plus optimale
- Résultats sensibles à l'initialisation aléatoire des centres
## PAM (Partitionning Around Medoids)
### Principe
- Utilise les Medoids qui sont des entités représentant le groupe dans lequel ils sont insérés, à la différence de K-means qui travaille avec des centroides
- Comme K-Means, PAM prend en paramètre le nombre de clusters
- Fonctionne avec une matrice de dissemblance (de coût) dont le but est de réduire un minimum la dissimiliarité globale entre les représentants de chaque groupe et ses membres. On cherche à minimiser l'évualuation de la matrice de coût.
Déroulement :
- Phase de construction :
1. Choisir (de façon aléatoire) autant de d'entités pour devenir des médoids qu'il y a de clusters à constituer
2. Calculer la matrice de dissemblance (de coût)
3. Attribuer à chaque entité son médoid le plus proche : constitution d'un cluster
- Phase de Swap
4. Pour chaque cluster, on cherche pour chaque entité si désigner l'une des entités comme nouveau medoid diminue le coût, le désigner en tant que medoid si c'est le cas
5. Si un medoid a changé repasser à 3, sinon fin de l'algorithme
### Exemple
Déroulement sur les données suivantes pour 2 clusters :
| Observation | $x$ | $y$ |
|-------------|---|---|
| $X_1$ | 2 | 6 |
| $X_2$ | 3 | 4 |
| $X_3$ | 3 | 8 |
| $X_4$ | 4 | 7 |
| $X_5$ | 6 | 2 |
| $X_6$ | 6 | 4 |
| $X_7$ | 7 | 3 |
| $X_8$ | 7 | 4 |
| $X_9$ | 8 | 5 |
| $X_{10}$ | 7 | 6 |
On choisit pour medoid X2 et X8, on calcul les matrices de dissemblances :
| i | Distance à X2 | Distance à X8 |
|----|--------------------------|--------------------------|
| 1 | **3** | 7 |
| 3 | **4** | 8 |
| 4 | **4** | 6 |
| 5 | 5 | **3** |
| 6 | 3 | **1** |
| 7 | 5 | **1** |
| 9 | 6 | **2** |
| 10 | 6 | **2** |
On a ${ Cluster_1 = \{ X_1, X_3, X_4 \} }$ et ${ Cluster_2 = \{ X_5,X_6,X_7,X_9,X_{10} \} }$
Et le Cout est égale à :
${ = (3+4+4) + (3 +1 + 1+2+2) }$
${ = 20 }$
Pour chaque non medoid, on calcule le cout potentiel si on le changeait en medoid. Si changer un medoid permet de faire baisser le coût, on accepte le changement.
Ici, on se rend compte le choix initial était le meilleur, aucune medoid n'est changé et l'algorithme s'arrête.
### Conclusions
- Plus rebustes aux données aberrantes
- Facile à mettre en oeuvre
- Converge rapidement
## CAH (Classification Ascendante Hiérarchique)
### Principe
- Créer à chaque étape une partition en agrégant deux à deux les éléments les plus proches (un élément étant un individu ou groupe d'individus)
- L'algorithme crée une hiérarchie de partitions, une sorte d'historique des fusions, permettant de retrouver l'état à $n$ partitions. Il s'agit du **Dendrogramme**
- Nécessite une métrique de distance (Euclidienne, Manhattan, Ward ...)
- Nécessite la définition de règle d'agrégation des individus et groupes d'individus
Exemple de Dendrogramme :
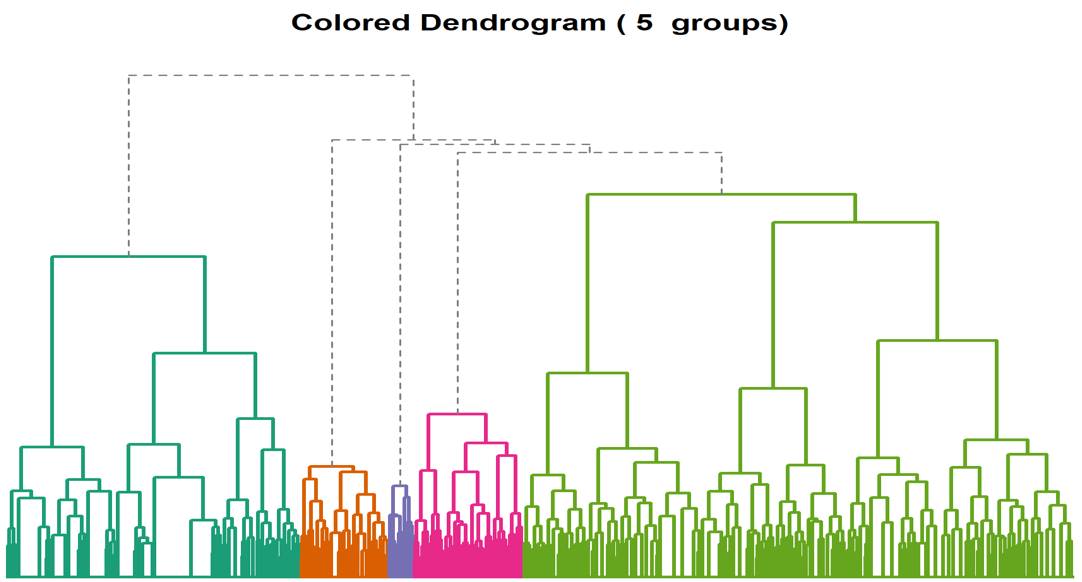
Le dendrogramme :
- Est le produit de la classification hiérarchique
- Indique les objets fusionnés à chque phase
- Indique la valeur du critère choisi pour chque partition
- Donne un résumé de la classification hiérarchique
- Chaque palier est une fusion de classes
- Le niveau d'un palier donne une indication sur la qualité de la fusion correspondante
- Toute coupure horizontale correspond à une partition
### Déroulement
Au début, on a $n$ et donc $n$ classes.
Ensuite, tant qu'on a plus d'une classe, on construit la matrice de distance et on regroupe les deux éléments les plus proches :
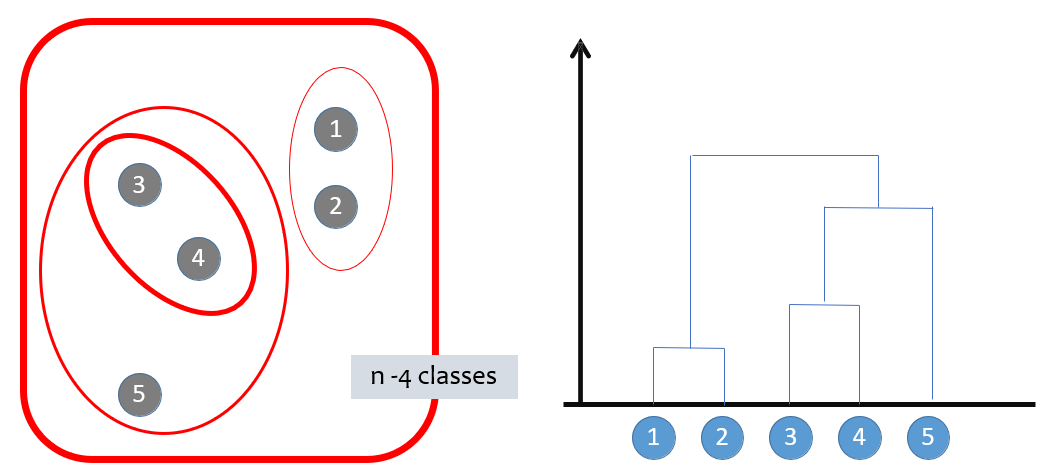
### Conclusion
- On a tout l'historique de la classification hiérarchique
- Il n'est pas nécessaire de définir le nombre de clusters à l'avance ; on peut explorer toutes les possibilités
## DB-SCAN (Density-Based Spatial Clustering of Applications with Noise)
### Problématique
DB-SCAN (et autre méthode de clustering par densité) visent à permettre de résoudre des problèmes de clustering impossible à résoudre correctement par les algorithmes précédents, comme par exemple la séparations de cercles imbriqués les uns dans les autres.
Les méthodes de clustering par densité se basent sur les observations suivantes :
- Deux points A et B peuvent appartenir au même clusters alors qu'il est impossible de créer une ligne au sein de ce cluster qui les relie
- On peut créer un chemin de proche en proche pour les rejoindre en restant dans le même cluster
- On peut les connecter par des **petits voisinages** contenant uniquement des points du même cluster
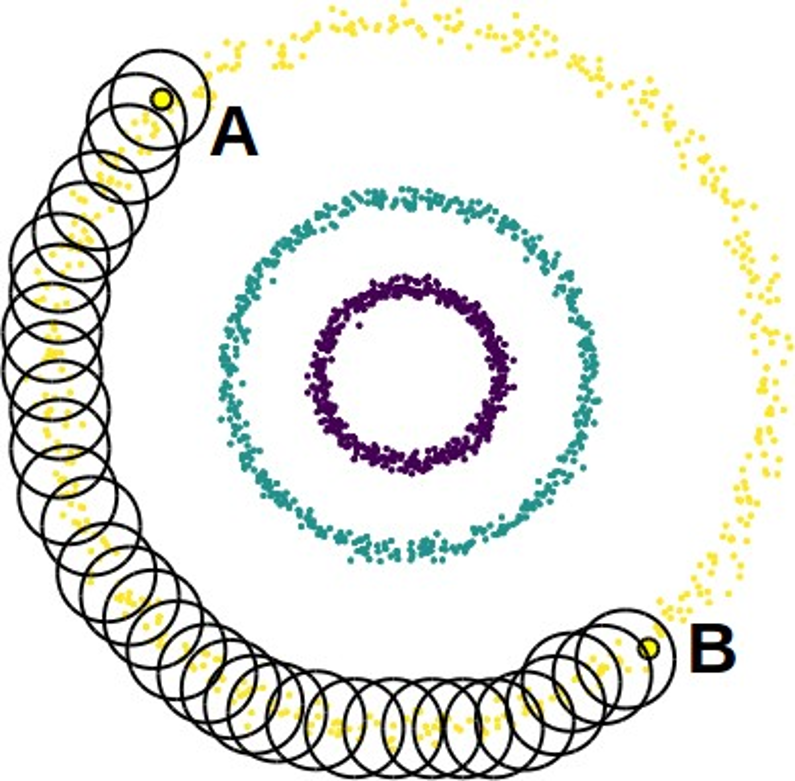
### Principe
1. Prendre un point $x$ non visité
2. Construire ${N = voisinage(\epsilon, x)}$
3. Si ${|N| < n_{min}}$ alors marquer $x$ comme bruit, sinon initialiser un nouveau cluster ${ C = \{x\}}$ et exécuter ${aggrandirCluster(C,N,eps,n_{min})}$
Avec :
- ${\epsilon}$ la taille définie d'un voisinage
- ${n_{min}}$ nombre minimum d'éléments définis pour la formation d'un cluster
- ${voisinage(\epsilon, x)}$ retourne l'ensemble des points à une disance ${\epsilon}$ de $x$
- ${|N|}$ : nombre d'éléments dans l'ensemble $N$
- ${aggrandirCluster(C,N,eps,n_{min})}$ :
- Pour chaque éléments $u$ dans $N$ :
- Si $u$ n'as pas été visité alors ${N' = N(eps,u)}$
- Si ${|N'| >= n_{min} }$ alors ${N = N \bigsqcup N'}$
- Si $u$ n'appartient à aucun cluster alors ajouter $u$ à $C$
### Conclusion
Avantages :
- Capable de produire des partitions non linéairement séparées
- Pas besoin de fournir le groupe à construire
- Robuste à la présence de points abérants
- Solutaion finale pas forcément affectée par le point de départ
Inconvénients :
- Les points frontières d'un cluster peuvent faire partie de l'un ou l'autre des cluster en fonction de l'ordre de traitement
- Repose fortement sur la mesure de distance
- Pas évident de calibrer des bonnes valeurs de $\epsilon$ et $n$
\newpage{}
# Evaluation
Il faut évoluer les modèles pour répondre aux questions suivantes :
- Pour savoir si le modèle est significatif : le modèle traduit-il une vraie causalité ?
- Quels seront les coûts de l'utilisation du modèle au déploiement ?
- Comparer plusieurs modèles candidats : lequel sera le plus efficace par rapport aux objectifs ?
On évlue les modèles sur des données de test en opération une séparation Train-Test : on va garder un proportion (20 ou 30%) de notre dataset hors des données d'entrainement afin de pouvoir les utiliser pour les tests.
## Métriques d'évaluation des modèles d'apprentissage supervisé
### Régression
Soit :
- $n$ nombre d'observation dans l'échantillon de test
- $y_i$ valeur de la variable cible dans l'échantillon de test pour l'observation $i$
- $y'_i$ valeur de la variable cible prédite par le modèle pour l'observation $i$
#### RMSE
Formule : ${ \sqrt{ \frac{1}{n} \sum_{i = 1}^n (y_i - y'_i)^2 }}$
RMSE varie entre 0 et $+\infty$. Le modèle idéal minimise cette mesure ; le modèle idéal a RMSE à 0.
#### MAE (Mean Absolute Error)
Formule : ${ \frac{1}{n} \sum_{i = 1}^n |y_i - y'_i| }$
MAE varie entre 0 et $+\infty$. Le modèle idéal minimise cette mesure ; le modèle idéal a MAE à 0.
#### $R^2$ et $R_{adj}^2$
${R^2 = 1 - \frac{ \frac{1}{n} \sum_{i = 1}^n (y_i - y'_i)^2 }{ \frac{1}{n} \sum_{i = 1}^n (y_i - \bar{y})^2}}$
Avec $\bar{y}$ la moyenne des valeurs de la variable cible dans l'échantillon de test
${R_{adj}^2 = 1 - [ \frac{ (1 - R^2)(n-1) }{n-k-1} ]}$
Avec $k$ le nombre de variables prédictives
$R^2$ et $R_{adj}^2$ varient entre 0 et 1. Le modèle idéal maximise cette mesure ; le modèle idéal a $R^2$ et $R_{adj}^2$ à 1.
### Classification
#### Matrice de Confusion
La matrice de confusion confronte les valeurs réelles de la variable cible avec les valeurs prédites.
Exemple avec les classes : "positif" et "négatif"
| Observées/ Prédites | Positif | Négatif | Total |
|---------------------|---------|----------|-------|
| Positif | a | b | a + b |
| Négatifs | c | d | c + d |
| Total | a + c | b + d | n |
- a : Nombre de Vrais Positifs, les observations prédites comme étant "positif" et qui le sont réellement
- b : Nombre de Faux Négatifs, les observations prédites comme étant "négatif" alors qu'elles sont en réalités "positif"
- c : Nombre de Faux Positifs, les observations prédites comme étant "positif" alors qu'elles sont en réalités "négatif"
- d : Nombre de Vrais Négatifs, les observations prédites comme étant "négatif" et qui le sont réellement
- n : nombre d'observation
Cette matrice nous apporte des informations sur la qualité d'apprentissage. On peut connaître le taux de réussite du modèle pour chaque classe. On peut calculer d'autre métriques :
- Rappel / Taux de vrais positifs / Sensibilité : ${ \frac{a}{a+b} }$
- Taux de faux positifs : ${ \frac{c}{c+D} }$
- Précision : ${ \frac{a}{a+c} }$
- Spécificité : ${ \frac{d}{c+d} }$
#### Courbe ROC (Receiving Operating Characteristics)
##### Problématique
Le taux d'erreur est un taux trop réducteur, notamment en cas de distributions très déséquilibrées (99% des observations dans une classe, 1% dans l'autre), car dans ce cas là, prédire systématiquement la classe majoritaire produit un "bon" taux d'erreur. Or un tel modèle ne sert à rien.
La solution est de changer de métrique d'évaluation. On va utiliser la courbe ROC.
##### Principe
Prérequis :
- Classification binaire
- Modalité d'intérêt : une classe qui nous intéresse plus que l'autre
La courbe ROC est un outil d'évaluation et de comparaison des modèles.
- Permet de savoir si un modèle donné sera toujours meilleur qu'un autre
- Opérationnel même dans les cas des distributions très déséquilibrés
- Résultat valable même si l'échantillon test n'est pas représentatif
- Un outil graphique permet de visualiser les performances (courbe) ; on peut identifier les modèles intéressants d'un coup d'oeil
- Un indicateur synthétique associé (score AUC) qui est aisément interprétable
Exemple de courbe ROC :

- En ordonnée : Taux de Vrais Positifs (sensibilité)
- En abscisse : Taux de Faux Positifs (spécificité)
- AUC : Area Under the Curve / Air Sous la Courbe
Score AUC :
- Entre 0 et 1
- Le modèle idéal a un score de 1
On se base sur le score AUC pour comparer les modèles.
##### Cas Parfait
Dans le Cas Parfait, on a une courbe toujours "au dessus" d'une autre. Cela signifie qu'il n'y a aucune situation dans laquelle le modèle au dessus est moins bon que l'autre.
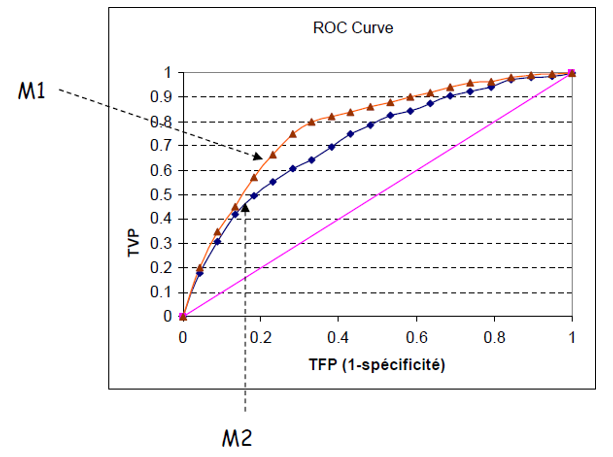
Ici : M1 sera toujours meilleur que M2
##### Chevauchement des courbes ROC
**L'enveloppe convexe** : formée par les courbe qui à un moment ou un autre n'ont aucune courbe "au dessus" d'elles.
- Les modèles dont la courbe constitue l'enveloppe convexe sont potentielles les modèles les plus performants pour une matrice de coûts donnée
- Les modèles dont la courbe de constituent pas l'enveloppe convexe sont toujours dominés par d'autres et peuvent être éliminés
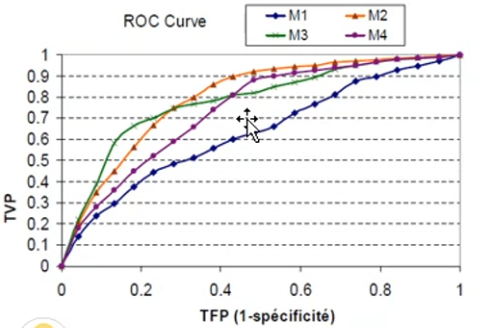
Ici :
- M1 est toujours dominé, il est éliminé d'office
- M4 est parfois meilleurs que M3 mais toujours moins que M2, il peut être éliminé
##### Conclusion
La courbe ROC est souvent un meilleur indicateur que le taux d'erreur.
- Surtout en cas de cas de classe déséquilibrées et quand le coup de mauvaise affectation est susceptible de modifications
- /!\ Il faut avoir une classe cible positive clairement identifiée (modalité d'intérêt) et une méthode d'apprentissage qui puisse fournir un Score proportionnel à une probabilité d'affectation vers la classe cible positive (c'est le cas de la plupart des méthodes d'apprentissage)
\newpage{}
# Deep Learning
## Définition
Classe d'algorithmes de machine learning spécialisés dans l'apprentissage à partir de données non structurées.
## Domaines d'application
- Médecine (diagnostiques)
- Automobile
- Cybersécurité
- Deepfake and Deepfake Detection
- MultiMedia Forensics
- Sales
- Réseaux sociaux
- Sécurité (prédiction de crimes)
- Détection de fraudes
- Détection de visages (et expression faciles)
## Différences avec le Machine Learning "Classique"
La Deep Learning permet d'exploiter des datasets beaucoup plus grand que le machines learning "classique" pour lequel les performances plafonnent.
Le Deep Learning tente également de modéliser avec un haut niveau d'abstraction des données. Il apprennent une représent (à plusieurs niveau) en utilisant une hiérarchie de plusieurs couches.
Ainsi, dans le machine learning, l'extraction des features est faite par l'homme, alors que dans le Deep Learning, il est effectué par la machine.
Si un algorithme de machine learning classique fait une prédiction inéxacte, un humain doit intervenir pour l'ajuster. Mais avec le deep learning, l'algorithme peut déterminer lui-même si un prédiction est exacte.
## Concept
### Modèle de base : le neurone Artificiel
Le modèle du neurone artificiel (appelé perceptron) est inspiré du neurone biologique :
- Prend en entrée $n$ informations
- Applique une fonction sur ces informations
- Renvoie une ou plusieurs valeurs de sortie pouvant être continues ou binaires
Le Deep Learning repose sur la construction de réseau de neurones artificiels organisés en couches, avec des interconnexions limitées aux couches adjacentes.
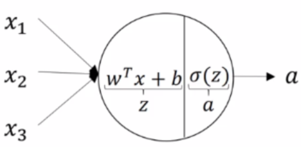
Il possède deux parties :
- La première clacule la sortie $Z$, en utilisant les entrée ($x+b$) et le poids $W^T$
- La seconde applique la fonction d'activation sur $Z$ pour donner la sortie finale $A$ du neurone
Plus $|W_i|$ pour une entrée $i$ est grand, plus le neurone prend en compte cette entrée. Si il est nul, l'entrée n'a pas d'influence.
### Réseaux de neurones
Les réseaux de neurones possèdent des poids entre toutes les deux couches. La transformation de la doublure de ces poids et les valeurs dans les couches précédentes passe par une fonction d'activation non liénaire pour produire les valeurs de la couche suivante. Ce processus se produit couche à couche, les valeurs optimales de ces poids peuvent être découverts afin de produire des sorties précises données à une entrée.
### Exemple
1. Initialiser le réseau avec des poids aléatoires
2. Présenter une donnée d'entrainement et comparer le résultat avec le résultat cible
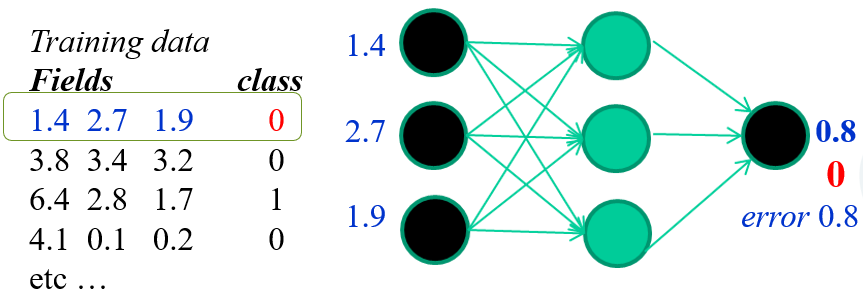
3. Ajuter les poids en fonction de l'erreur, par mécanisme de rétropropagation
→ Répétez ces étapes des milliers / millions de fois
## Fonctions d'activation
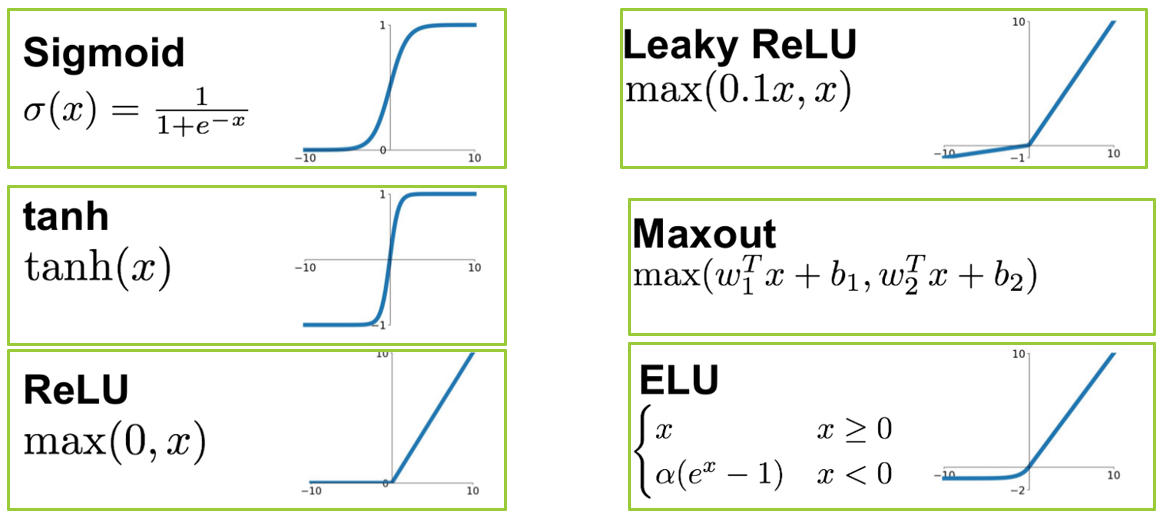
Les fonctions d'activation $\sigma$ est une fonction appliquées à chaque noeud pour obtenir se sortie. Elles permettent de rendre le réseau robuste pour qu'il fonctionne bien dans différents scénarios, en introduisant des propriétés non linéaires, afin de généraliser ou de s'adapter facilement à la variété des données.
La fonction d'activation va cartographier la sortie du réseau comme "oui" ou "non" et cartographie les valeurs selon la fonction. Il en exéiste deux types :
- Linéaires
- Non linéaires
Exemples :
- ReLU
- Sigmoid
- Tanh
- Leaky ReLU
\newpage{}
# Outils Python
Pour appliquer le machines learning nous avons utilisé des librairies et frameworks en Python.
## Numpy
- Package Python spécialisé dans la manipulation de tableaux multi-dimensionnels
- Basé sur la structure de donnée `ndarray`, un tableau multidimensionnel
- Contient un grand nombre de routine pour faire des opérations sur les données :
- Recherche
- Extraction
- Tri
- Algèbre linéaire
- Statistiques
- ...
- Les tableaux Numpy sont plus efficaces et performants que les collections de base de Python
## Pandas
- Package Python (basé sur Numpy) spécialisé dans la manipulation de données structurées au format tabulaire.
- Propose deux structures de données performantes :
- `Series` : vecteur Numpy avec indices nommés
- `DataFrame` : collection de `Series` avec les mêmes indices
- Propose plusieurs fonctions et méthodes pour effectuer des tâches d'analyse de données comme :
- Transformations
- Aggrégations
- ...
On peut créer des `DataFrame` à partir :
- D'un dictionnaire Python
- D'un fichier CSV
- D'une base SQLite
## Matplotlib
- Package Python pour la visualisation de donnée
- Propose des fonctions pour la création de graphiques 2D et 3D
- Pyplot est un module de Matplotlib qui permet de créer des visualisations interactives
## Seaborn
- Bibliothèque de visualisation de donnée basée sur Matplotlib
- Fourni une API de plus haut niveau pour créer des graphiques interactifs statistiques
## Scikit Learn
Librairie qui expose une API unifiée et de haut niveau pour entrainer des modèles de machine learning.
Scikit Learn utilise Numpy et est compatible avec les `DataFrame` de Pandas.